

【活動簡介】
當團隊對「驗收標準」沒共識,只會把錯誤做得更完整。
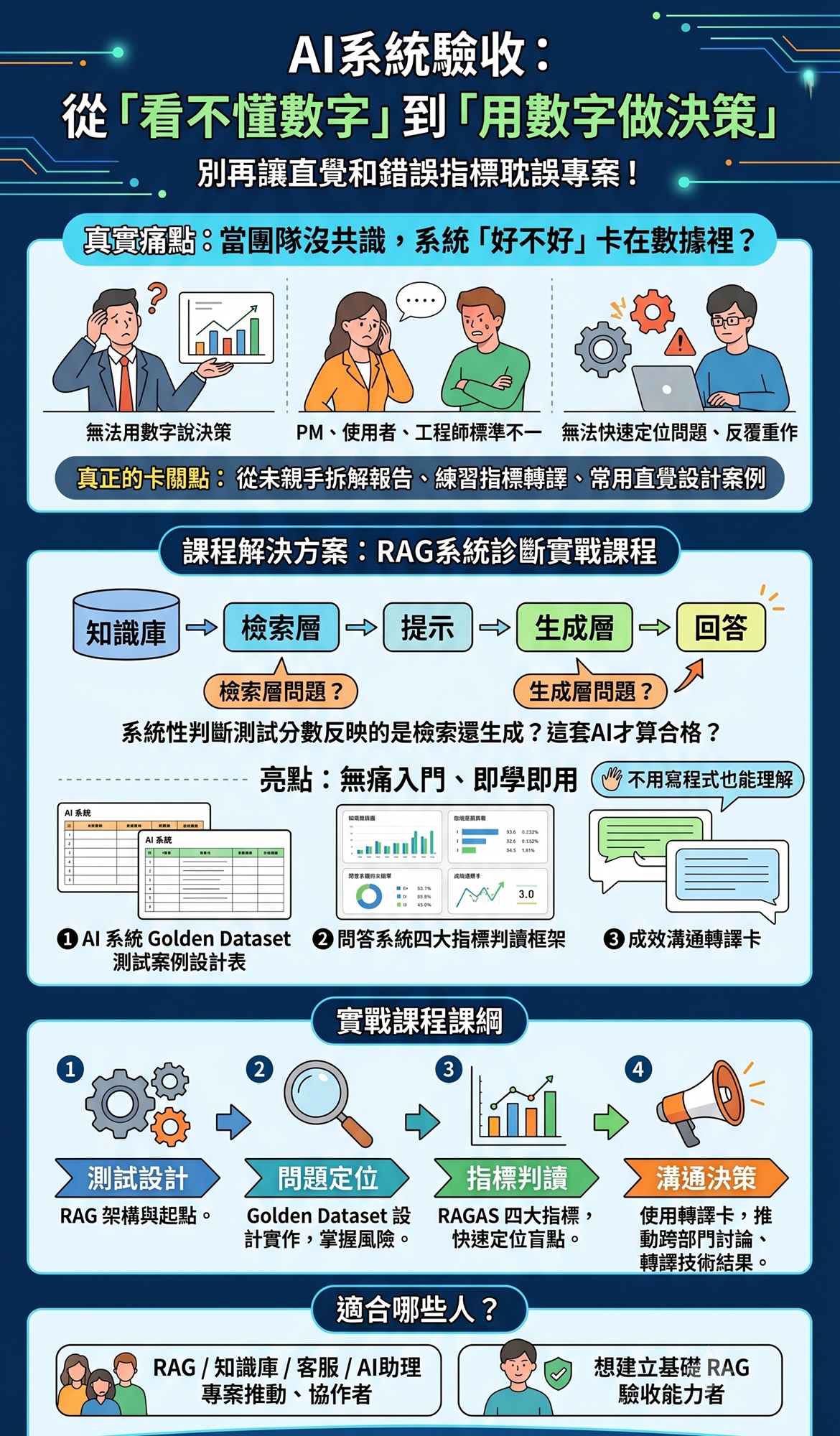
專案會議上,主管問到「這個系統現在到底夠不夠好?」
你看著那份測試報告,分數看起來還不錯,卻說不出有把握的答案。驗收 AI 系統,卡住你的不是看不懂數字,更重要的是不知道「怎麼用數字說話」。
PM、使用單位、工程師對驗收目標沒共識,讓你左右為難;
數字擺在眼前,卻無法翻譯成讓主管或客戶點頭的決策語言;
系統回答開始出錯,但你無法快速定位問題責任,最後反覆重作。
你嘗試自己摸索,卻還是有看沒有懂,真正的卡關點在於:
你從沒有親手拆解過一份測試報告、沒練習過把指標數字轉成對方聽得懂的一句話、常用直覺設計測試案例。下次遇到一樣的場面,你還是會停在原地。
本課程帶你實際以業界常用的 RAG 問答系統為主要場景,教你用一套可複用的診斷框架,系統性地判斷:
「測試分數反映的是檢索層、還是生成層問題?」、「測試案例該包含哪些問題類型,這套AI才算合格?」從企業案例著手,加入驗收情境實戰演練,未來面對不同專案或系統不再只憑感覺下判斷。
|無痛入門|附真實測試案例拆解與操練指令,不用寫程式也能理解問題怎麼發生
|即學即用|三種實戰工具帶回家,不只看懂數字,更協助你降低錯誤決策風險
❶ Golden Dataset 設計表
❷ RAGAS 四大指標驗收評量表
❸ 跨部門驗收溝通範本
【實戰課程課綱】
測試設計|驗收從哪裡開始?理解 RAG 系統架構與測試起點
問題定位|Golden Dataset 測試案例設計表實作演練,掌握真實風險
指標判讀|RAGAS 四大指標判讀,看懂分數背後盲點,快速定位問題來源
溝通決策|使用跨部門溝通範本,推動跨部門討論、技術結果轉譯為更好懂的決策依據
【適合哪些人】
- AI 問答系統/RAG 知識庫/客服問答/內部AI 助理等專案推動、協作者
- 想預先建立 RAG 系統測試、驗收與成效判讀基礎者
