【SELECT * FROM 資料小聚】
#001主題|不藏私公開: 專案貢獻者的開源專案應用情境分享
資料競賽時代正式來臨!數據分析師們都想盡辦法針對各家企業業務分析,讓資料驅動決策這件事,成為The Next Big Thing。本次小聚將由三位工程師分享使用開源的經驗,讓大家更清楚瞭解如何用開源協助分析工作。以及一位資料科學家分享工作日常,與大家一起交換心得!
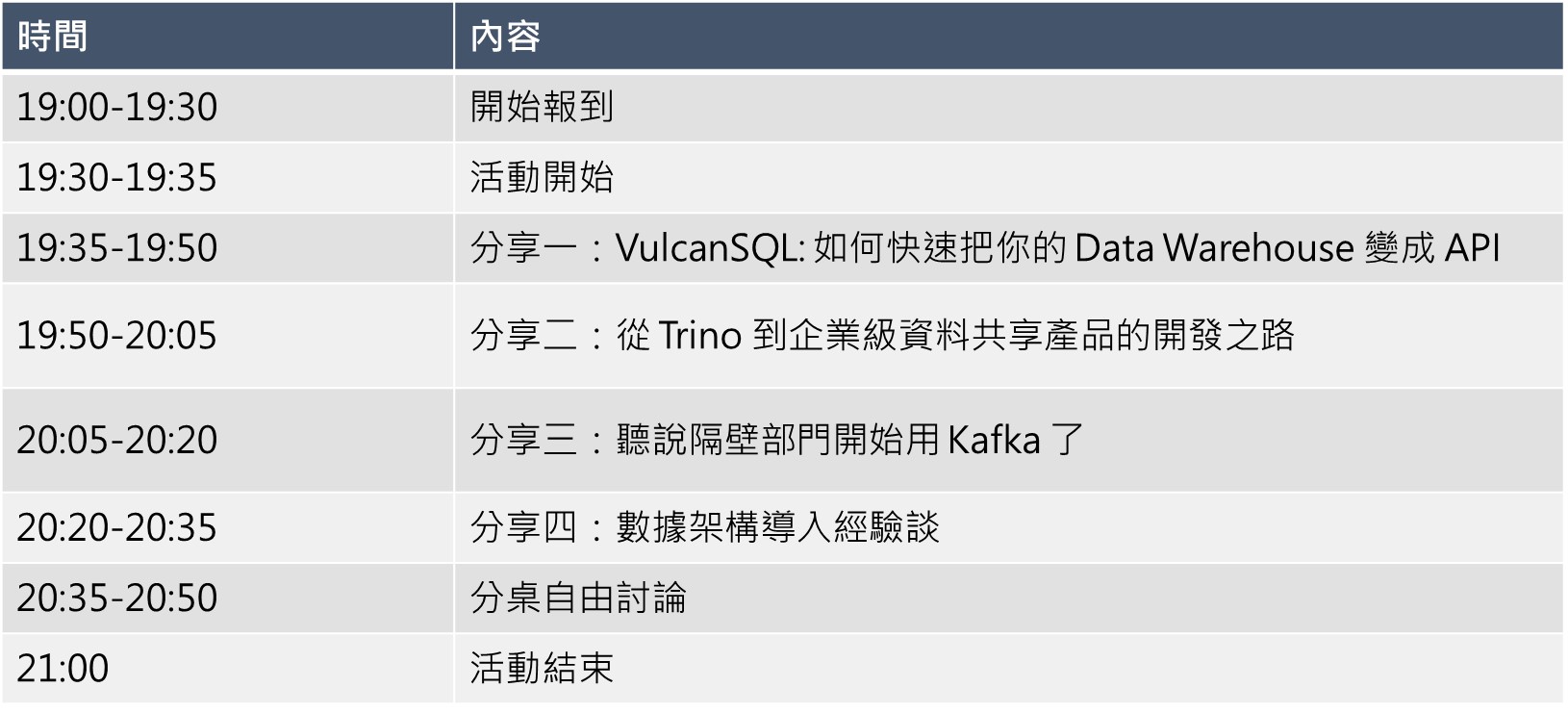
請注意,本次活動每輪分享僅15分鐘,Speed Run !
▍分享一|VulcanSQL: 如何快速把你的 Data Warehouse 變成 API
VulcanSQL 提供 data analyst 資料共享的 API 開發框架,只用 SQL 就可以快速把 data warehouse 轉成可對內對外使用的 API,文件自動產生,後台也自動產生,不會 SQL 的使用者也可以透過 VulcanSQL 的後台做資料串接 / 下載 CSV 等操作
講者:Eason Kuo

Eason 郭奕成,現職 Canner 易開科技的後端工程師。熱於研究導入各種企業級應用之軟體架構模式,曾為微軟 MVP 與 Domain Driven Design Taiwan 社群的核心志工與講師,現則是 VulcanSQL 開源項目的共同開發者之一。
▍分享二|從 Trino 到企業級資料共享產品的開發之路
Canner 在 Trino 之上提供企業級的資料共享解決方案,基於 Trino 做了不小的修改,很多修改也貢獻回到社群。這次分享中,介紹我們 canner 實作在 trino 上的企業需要的功能,也著重在 connector 的動態更新做深度介紹
講者:Cooper Tseng

Cooper Tseng 曾冠博,現職為 Canner 易開科技的資料工程師。致力於資料處理系統的研究與開發,曾貢獻 HBase, Trino 等開源專案,現今主要活動於 Trino 社群。
▍分享三|聽說隔壁部門開始用 Kafka 了
Kafka 為世界級熱門的大數據事件串流處理系統,本次分享將介紹 Kafka 的使用方式、應用案例、以及遇到Kafka疑難雜症時可參考的線上資源。
講者:Chia Ping
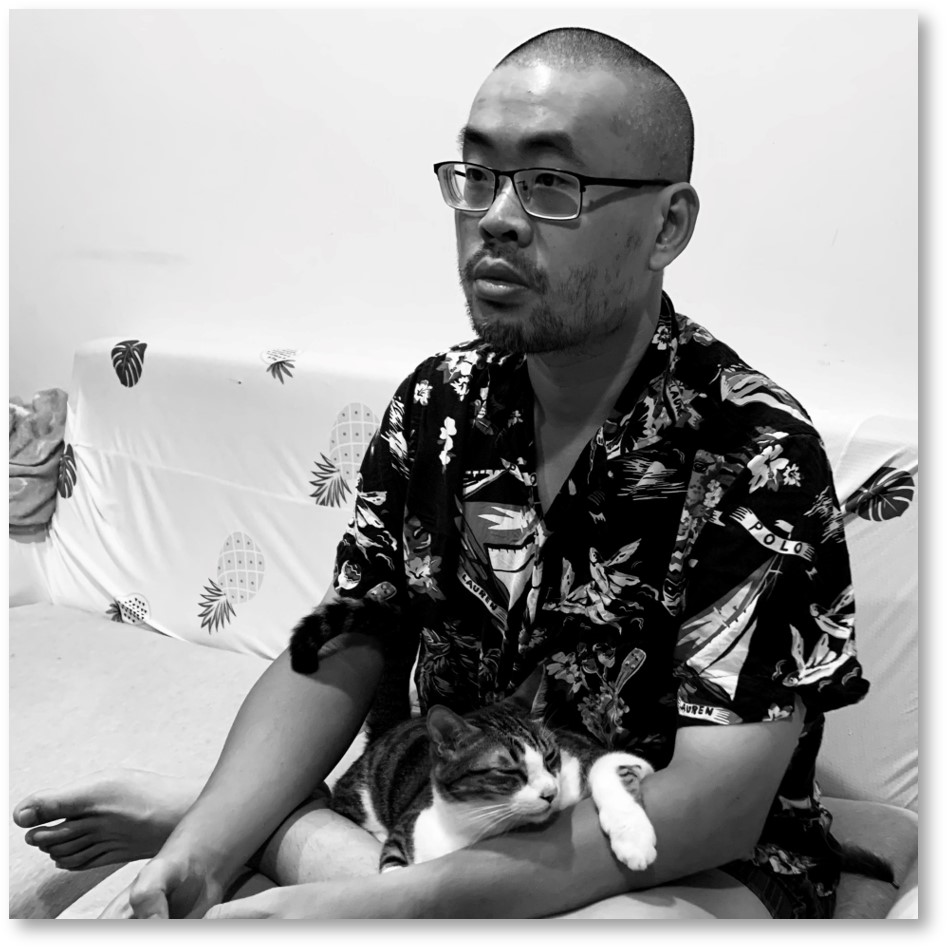
Chia-Ping Tsai 蔡嘉平博士,現職為亦思、原昌和教育部人培的開源技術顧問,同時也是HBase, Kafka, Yunikorn的核心開發者 (committer & PMC),另外也是 Apache Member 和 HBase, Kafka 官方研討會的委員。最近重心放在推廣 Kafka 技術到台灣的各個領域
▍分享四|數據架構導入經驗談
資料分析能夠幫助企業用更量化的方式解決問題,但是在導入的過程中會面臨許多不同的挑戰。本次議題將分享過去在不同單位的數據導入的經驗談,如何隨著業務量的增長調整資料架構與團隊數據文化的階段性任務。在導入的過程中我們透過不同的開源工具,逐步建立「#人人都是資料分析師」的團隊分工。
講者:維元

擅長網站開發與資料科學的雙棲工程師,熟悉的語言是 Python 跟 JavaScript。同時經營資料科學家的工作日常 Facebook 粉專 與 Instagram 社群,擁有多次國內大型技術會議講者經驗,持續在不同的平台發表對 #資料科學、 #網頁開發 或 #軟體職涯 相關的分享。
【活動資訊】
⚠️本場為實體活動,敬請把握名額,切勿臨時取消或缺席。
⚠️防疫期間,本活動現場備有茶水,但不提供餐點,敬請見諒!
►主辦單位:Canner
►地點:中山區伊通街47號 B1 (布萊梅桌遊專賣店,鄰近南京松江站)
►時間:111年9月29日 (四) 19:30-21:00 (19:00開始報到)